Desplegar una Respuesta a Incidentes de ciberseguridad de manera efectiva, es una tarea compleja que requiere de una planeación exhaustiva, revisión y actualización permanentes, así como de recursos humanos (especialización y entrenamiento constante) y tecnológicos .
Para establecer acciones de respuesta ante incidentes en las organizaciones, existen hoy en día en la industria de Ciberseguridad infinidad de guías, documentación, recomendaciones, para este fin y una de las organizaciones más reconocidas en este rubro, como lo es NIST (National Institute of Standars & Technology), cuenta con una Guía para el Manejo de Incidentes de Seguridad (SP800-61). La misma es de acceso público y es reconocida como estándar de referencia en el manejo incidentes de seguridad informáticos.
Dicha guía establece 7 etapas a seguir para un manejo adecuado de incidentes:
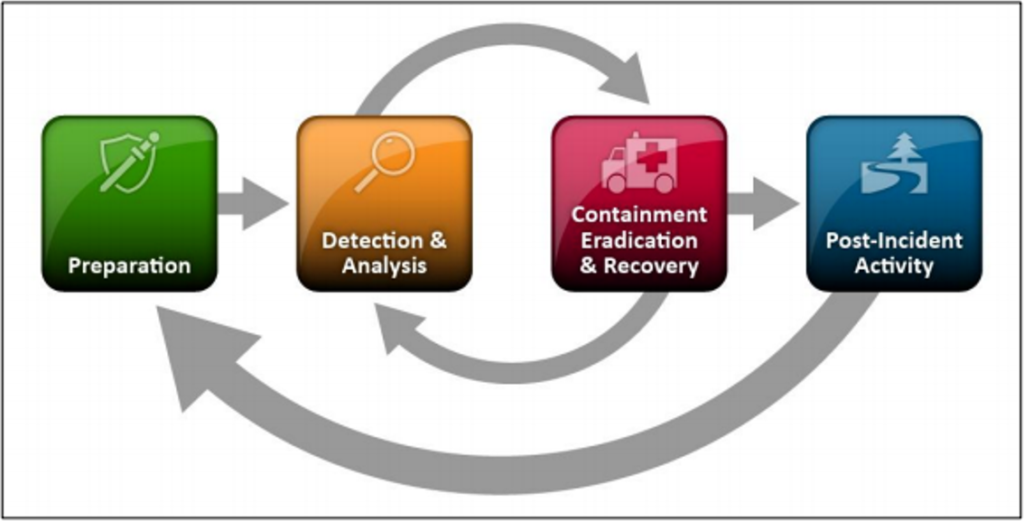
Enseguida se describen los puntos más importantes de cada una de ellas:
- Tener conformado un equipo de respuesta a incidentes, con la preparación y experiencia para poder atender, dar seguimiento y solución a cualquier incidente de seguridad.
- Contar con un Plan de Respuesta ante Incidentes, que defina de manera clara y secuencial (se recomienda hacerlo a manera de checklist), los pasos a seguir ante un incidente de seguridad.
- Tener preparado Hardware y Software para análisis de incidentes, tal como:
- Software (como EDR) y/o Hardware para la recolección de datos forenses digitales y respaldo de información.
- Laptops para tareas de análisis de datos, análisis de trafico de red, redacción de reportes.
- Analizadores de paquetes y protocolos de red.
- Tener identificada y documentada la infraestructura de TI de la organización:
- Diagramas de red y tener enlistados los activos más importantes (como servidores críticos).
- Tener clara y documentada la forma normal actual de operar (Baseline) de la red y aplicaciones.
- Tener identificada la lista de puertos utilizados en la red.
- Hashes criptográficos de archivos críticos.
Como guía de referencia sobre las acciones a llevar a cabo en esta y todas las demás etapas del modelo NIST, es de gran utilidad y claridad diseñar o utilizar Playbooks ya creados por otras organizaciones reconocidas, como es el caso de los diseñados por Insident Response Consortium, que son de acceso público y se utilizarán como referencia en este artículo.
El playbook que se usará como referencia específicamente es el de MALWARE OUTBREAK. Y el correspondiente a la etapa de Preparación es el siguiente:
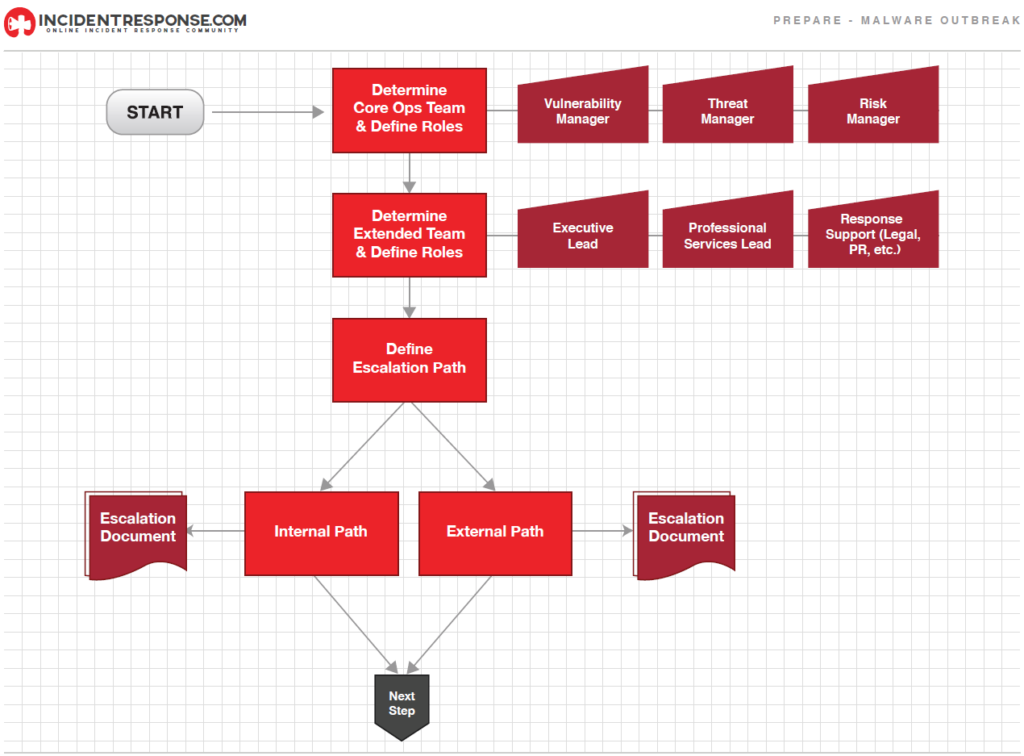
- Determinar si se trata de solo un evento (sin malas consecuencias para la organización) o en realidad es un incidente (con malas consecuencias para la organización, como violación de políticas o estándares de seguridad).
- Algunos de los indicadores o comportamientos más comunes que pueden ser señal de un incidente son:
- Existencia de usuarios desconocidos.
- Procesos o conexiones de red extrañas.
- Conexiones de red a la escucha.
- Llaves de registro inusuales.
- Tareas agendadas desconocidas, o servicios corriendo.
- Tener en cuenta los vectores de ataque, tales como (se mencionan los más comunes):
- Dispositivos externos/removibles (usb’s).
- Ataques de fuerza bruta (Attrition).
- Navegación, Email (Spear phishing, Bussiness Email Compromise).
- Explotación de vulnerabilidades (de sistema operativo, aplicaciones).
- Pérdida o robo de equipo.
- Ataques Man in the Middle (MIM).
- Las fuentes más comunes donde se puede encontrar indicadores de incidentes son:
- Sistemas SIEM.
- Software Antimalware y Antispam.
- Soluciones de File Integrity Checking.
- Servicios de monitoreo e información de seguridad y amenazas de terceros, Open Source (OSINT), Comerciales, Gubernamentales (como CERT’s, ISAC’s, Data Feeds).
- Logs de sistemas operativos, así como dispositivos de red (como UTM’s (IDS e IPS), routers, switches).
- Personas dentro y fuera de la organización, afines al área de Ciberseguridad.
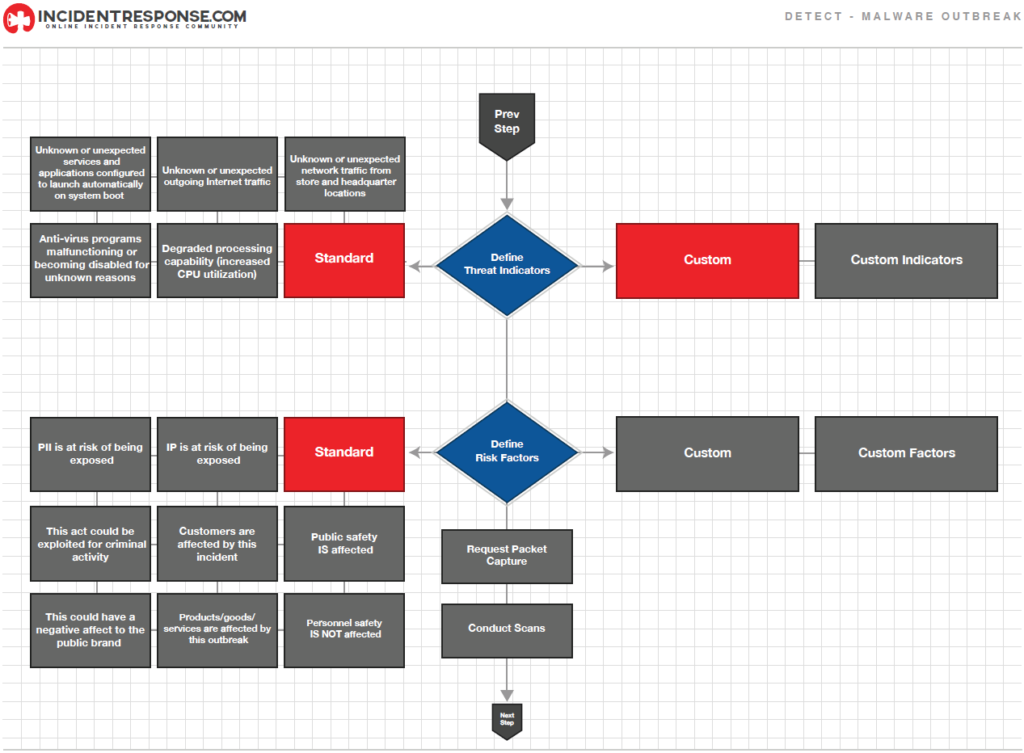
El equipo de respuesta a incidentes debe trabajar rápido para analizar y validar cada incidente, siguiendo un proceso predefinido y documentado cada paso realizado.
El análisis inicial debe proveer información suficiente para priorizar (triage) actividades subsecuentes, como la contención del incidente y análisis más profundo de los efectos y alcance del incidente.
Las siguientes son recomendaciones para hacer el análisis de incidentes más fáciles y efectivas:
- Entender comportamientos normales: El equipo de respuesta a incidentes debe analizar las redes, sistemas y aplicaciones de la organización, para entender cuál es su comportamiento normal (Baseline), de tal manera, cuando se presente un comportamiento anormal, sea más fácil de identificar.
- Crear una política de retención de logs: Crear e implementar esta política que especifique por cuanto tiempo los logs deben de mantenerse es de gran utilidad en el análisis porque principalmente los incidentes pueden ser descubiertos después de varios días, semanas o meses después de haber ocurrido (UTM’s, Antimalware, Sistemas).
- Realizar correlación de eventos: La evidencia de un incidente puede ser registrada en logs de varios sistemas (UTM’s, Antimalware, Sistemas operativos, aplicaciones). Recomendado uso de solución SIEM.
- Mantener todos los relojes de los sistemas sincronizados: Hacer uso de protocolos como NTP, con el fin de mantener la sincronización entre hosts y evitar que los eventos sean inconsistentes en lo que respecta a su hora de ocurrencia, lo que dificulta en gran medida en análisis de incidentes.
- Hacer uso de motores de búsqueda en internet para investigar incidentes.
- Uso de analizadores de tráfico de red para la recolección de datos adicionales (como Wireshark).
- Filtrado de datos/logs: Una estrategia efectiva es filtrar categorías de datos significativos como eventos críticos e ir avanzando paulatinamente a el análisis de datos menos relevantes (aunque en muchas ocasiones este tipo de eventos revelan información importante sobre el incidente).
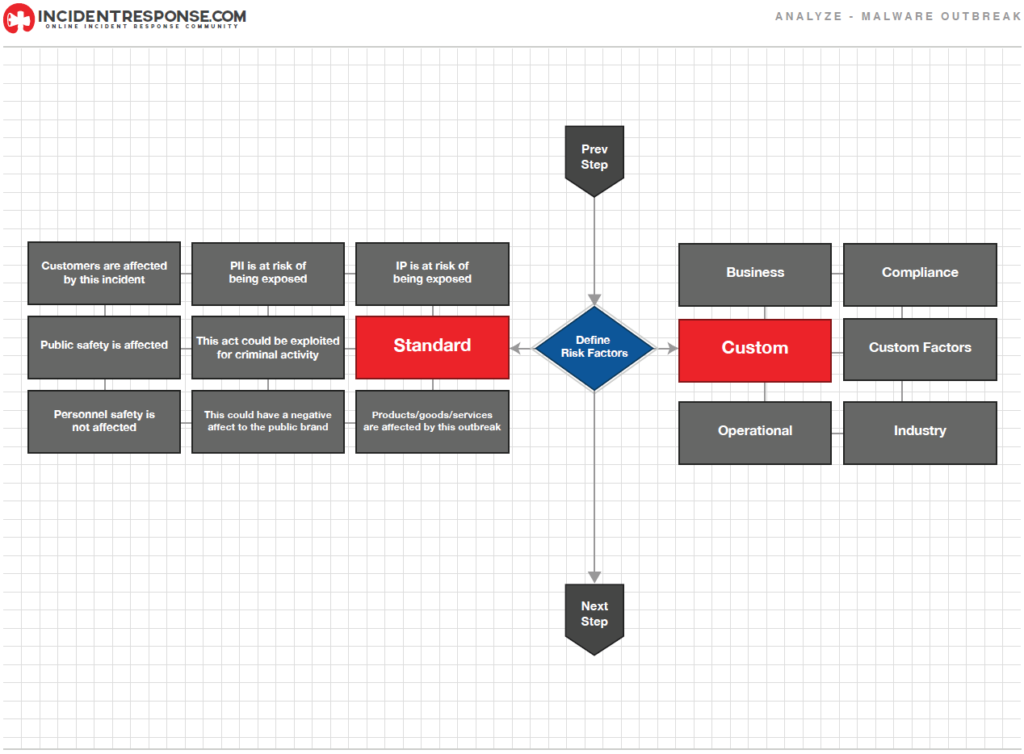
- Priorización del incidente: La priorización en el manejo del incidente es quizas, es el punto más crítico en la toma de decisiones en el proceso del manejo de incidentes.
Este debe ser priorizado en basandose en datos relevantes, tales como:- Impacto funcional del incidente: Ninguno, Bajo, Medio, Alto.
- Impacto del incidente en la información de la organización: Ninguno, Violación de Propiedad, Perdida de Integirdad.
- Recuperabilidad del incidente: Regular, No Recuperable.
- Notificación de incidentes: Definir los contactos y los medios por los cuales el personal debe reportar cualquier incidente de seguridad.
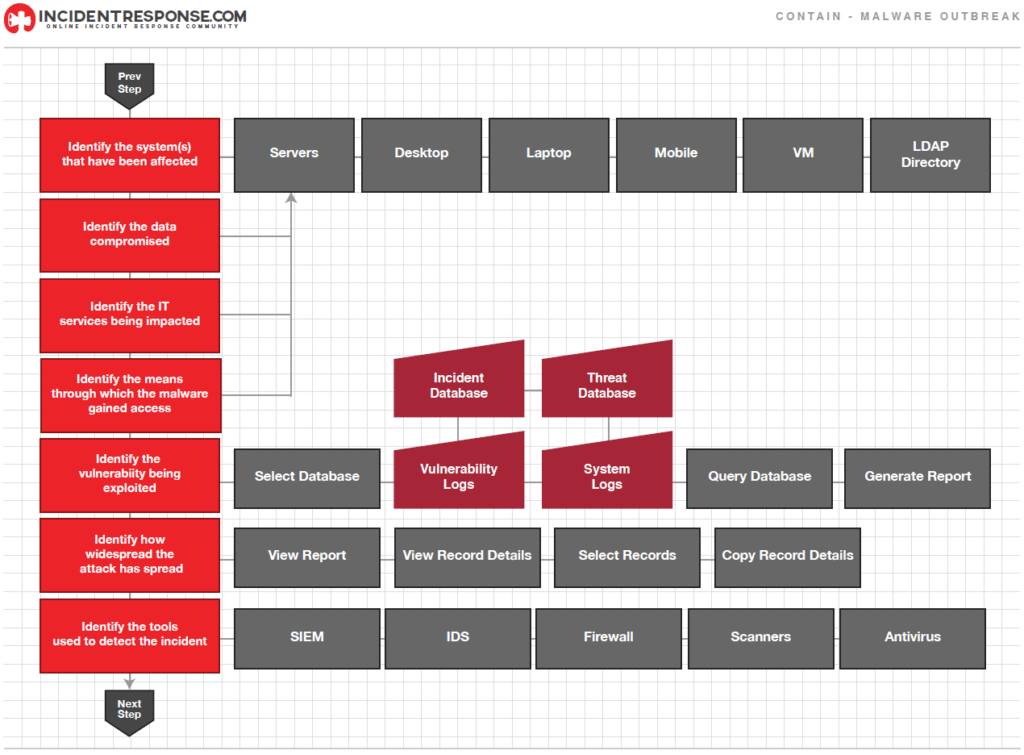
- Una parte esencial de esta etapa es la toma de las decisiones (por ejemplo, apagar un sistema, desconectarlo de la red, deshabilitar ciertas funciones, etc). El principal objetivo es prevenir un mayor daño y a su vez mantener las evidencias intactas. Las estrategias de contención varían de acuerdo al tipo de incidente. Las organizaciones deben crear estrategias de contención por separado, para cada tipo de incidente mayor, con criterios documentados y claros, para facilitar la toma de decisiones. Criterios para determinar una estrategia apropiada incluyen:
- Daño potencial y robo de recursos.
- Necesidad de preservación de evidencia.
- Disponibilidad de servicios (por ejemplo, conectividad de red, servicios proveídos a terceros).
- Tiempo y recursos necesarios para implementar la estrategia.
- Efectividad de la estrategia.
- Duración de la solución (workaround de emergencia a llevar a cabo por 4 horas, workaround temporal a remover en 2 semanas, solución permanente).
- En algunos casos se recomienda redirigir al atacante a un sandbox o honeynet, para que la organización pueda monitorear las actividades del atacante, usualmente para reunir evidencia adicional.
- Recolección y manejo de evidencia
- Es importante documentar claramente como toda la evidencia, incluyendo sistemas comprometidos, ha sido preservada. Para esto es necesario instrumentar una Cadena de Custodia, que documente cuando cualquier evidencia pase de una persona a otra y que incluya detalle y firmas de cada parte involucrada.
- La evidencia debe ser conservada a detalle, incluyendo los siguientes datos:
- Información de identificación (ubicación, números seriales, modelo, Hostname, IP, MAC del equipo).
- Nombre, cargo, no. Telefónico de cada individuo involucrado en la recolección o manejo de evidencia durante la investigación.
- Fecha y hora de cada manipulación de evidencia.
- Ubicaciones de donde fue guardada la evidencia.
- Identificación de los hosts atacados. Los siguientes componentes describen las actividades más comunes para la identificación de hosts atacados:
- Validar la dirección IP del host atacante.
- Investigación del host atacante a través de motores de búsqueda (search engines).
- Uso de bases de datos de incidentes: Diferentes grupos colectan y consolidan datos, como Indicadores de Compromiso (IOC’s) de diferentes organizaciones en bases de datos de incidentes. La compartición de esta información puede realizarse de diferentes maneras, tales como Threat Intelligence Platforms (TIP’s), CERT’s, Black-Lists en tiempo real. La organización puede consultar su propia base de conocimientos o realizar una consulta de los IOC’s identificados en el incidente y posteriormente hacer un rastreo en la red de la organización con la finalidad de identificar y neutralizar los componentes maliciosos del incidente.
- Monitorear los canales de comunicación del atacante.
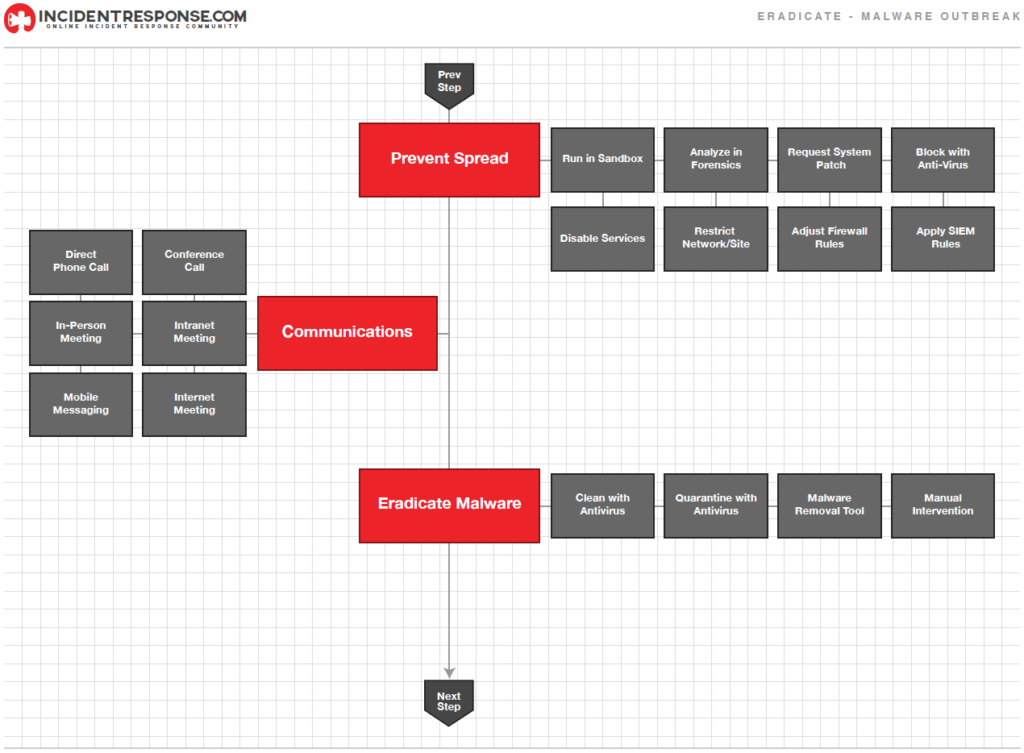
Posterior a la contención de un incidente, la erradicación es necesaria (aunque no siempre o se realiza en la etapa de recuperación) y es importante identificar todos los hosts afectados dentro de la organización para que puedan ser remediados. Algunas de las acciones a realizar en esta etapa son:
- Eliminar malware.
- Eliminar usuarios maliciosos o vulnerados.
- Parcheo de sistemas para mitigar vulnerabilidades utilizadas.
- Crear nuevas reglas en las soluciones de seguridad.
- Aplicar un análisis de vulnerabilidades a los sistemas y la red (Pen test).
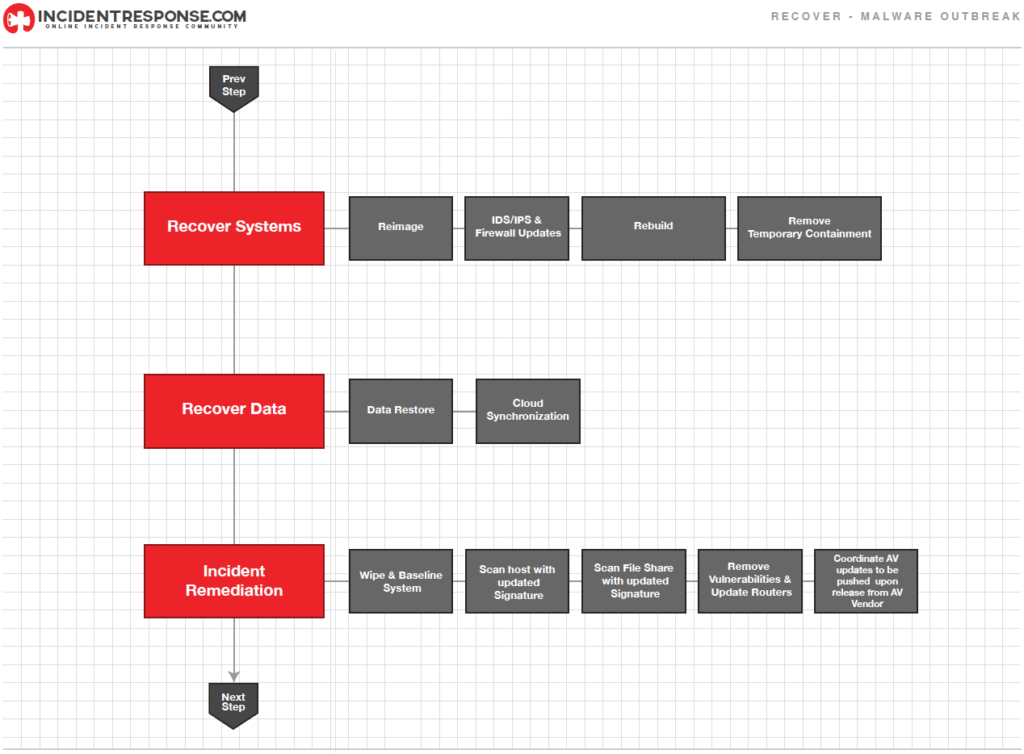
En esta etapa, administradores restauran los sistemas a su operación normal, confirman si están funcionando de manera correcta y (si aplica) se remedian vulnerabilidades para prevenir incidentes similares. Recuperación incluye acciones tales como:
- Restaurar sistemas desde respaldos limpios.
- Restaurar sistemas desde cero.
- Instalación de parches.
- Cambiar contraseñas en sistemas locales y recursos de red.
- Administradores deben monitorear sistemas para asegurarse de su funcionamiento normal.
- Continuar probando los sistemas restaurados.
- Documentar los pasos llevados a cabo.
- Recuperación permite a la contención empezar de nuevo, si la actividad maliciosa es detectada de nueva cuenta.
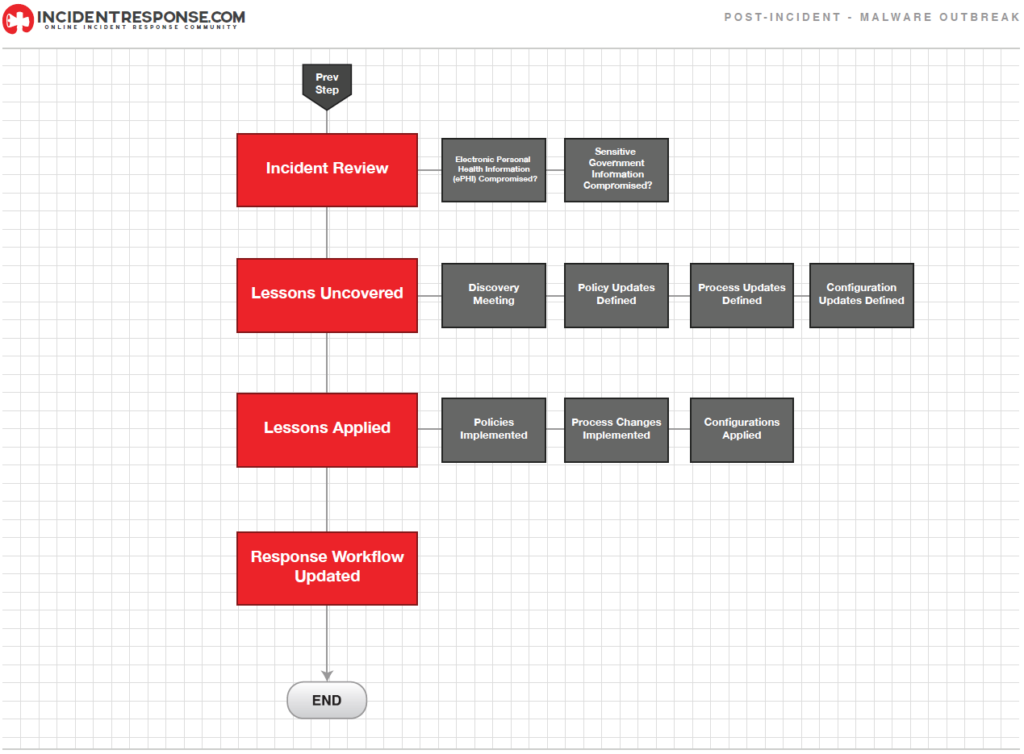
Una de las partes más importantes de la Respuesta a Incidentes es también comúnmente omitida: aprender y mejorar. El equipo de respuesta a incidentes debe evolucionar, tomando conciencia y conocimiento de las nuevas amenazas, tecnologías y lecciones aprendidas.
Mantener una reunión de “Lecciones Aprendidas”, con todas las partes involucradas en un incidente, puede ayudar en gran medida a mejorar las medidas de seguridad y el propio proceso de respuesta a incidentes. Preguntas a ser respondidas en estas reuniones son:
- ¿Qué sucedió exactamente y en qué momento (fechas y horas)?
- ¿Qué tan bien se desempeñó el equipo en la atención del incidente? ¿Se siguieron los procesos documentados? ¿Fueron los adecuados?
- ¿Qué información fue necesitada en primera instancia?
- ¿Se tomaron pasos o acciones que pudieron haber inhibido la recuperación?
- ¿Qué podría hacer el equipo de manera diferente la próxima vez que ocurra un incidente similar?
- ¿Cómo podría ser mejorado el mecanismo de compartición de información con otras organizaciones?
- ¿Qué acciones correctivas se pueden aplicar para prevenir incidentes similares futuros?
- ¿Qué indicadores deben ser observados en el futuro para detectar incidentes similares?
- ¿Qué herramientas o recursos adicionales se necesitan para detectar, analizar y mitigar futuros incidentes?
- Otra actividad importante en esta etapa es crear un “Reporte de seguimiento del Incidente“. Este reporte podrá ser usado como referencia para ayudar al manejo de futuros incidentes similares.
- Uso de la información colectada: El estudio de las características del incidente puede revelar la existencia de vulnerabilidades y amenazas sistemáticas, así como cambios en las tendencias de incidentes. Esta información puede ser tomada en cuenta para la realización del proceso de análisis de riesgos, lo que a su vez llevará a selección e implementación de controles adicionales.
Las organizaciones deben focalizarse en colectar información accionable, en lugar de recabar información simplemente porque está disponible. Métricas sugeridas para la recolección de incidentes son:- Número de incidentes atendidos: Se recomienda enfocarse en los incidentes de mayor relevancia o que necesitaron de un mayor esfuerzo por parte del equipo de respuesta a incidentes para su resolución.
- Tiempo utilizado por cada incidente.
- Análisis objetivo de cada incidente: Con esto se puede determinar qué tan efectiva fue la respuesta y resolución del mismo.
- Retención de la evidencia: Organizaciones deben establecer una política para definir por cuanto tiempo se resguardará la evidencia de un incidente. GRS (General Records Schedule), especifica que los registros de incidentes deben resguardarse por un periodo de 3 años.